floor,rank,select <재귀부분 이해[ ]
다이나믹 알고리즘 부분 [ ]
(실제 문풀을 어케 해야하는건지





1. 이진 검색 트리(BST)의 최소/최대값 찾기 (Min/Max)
교수님은 전체 트리에서 가장 작은 값(Min)과 가장 큰 값(Max)을 찾는 방법부터 설명을 시작하셨습니다.
- Min (최소값): 루트부터 시작하여 계속해서 왼쪽 끝까지 가면 가장 작은 값을 찾을 수 있습니다.
- Max (최대값): 루트부터 시작하여 계속해서 오른쪽 끝까지 가면 가장 큰 값을 찾을 수 있습니다.
[관련 코드: PDF 41페이지]
public K min() { // 제일 작은 키를 반환
if (root == null) return null;
Node<K,V> x = root;
while (x.left != null) // 제일 왼쪽에 있는 노드
x = x.left;
return x.key;
}
public K max() { // 제일 큰 키를 반환
if (root == null) return null;
Node<K,V> x = root;
while (x.right != null) // 제일 오른쪽에 있는 노드
x = x.right;
return x.key;
}2. Floor 연산 (바닥 함수)
floor(key)는 입력받은 키보다 작거나 같은 것 중에서 가장 큰 값을 찾는 함수입니다.
- 찾는 키가 노드의 키와 같으면: 해당 노드가 정답입니다.
(--------------여기부터 이해안됨-------------)
- 찾는 키가 노드의 키보다 작으면: 무조건 왼쪽 서브트리로 가서 찾아야 합니다.
- 찾는 키가 노드의 키보다 크면: 오른쪽에 답이 있을 수 있습니다. 하지만 오른쪽 서브트리에 조건에 맞는 키가 없다면(null이 리턴된다면), 현재 노드 자체가 작거나 같은 것 중 가장 큰 값이 되므로 현재 노드가 답이 됩니다.
[관련 코드: PDF 42페이지]
public K floor(K key) { // key보다 작거나 같은 키들 중에서 제일 큰 키
if (root == null || key == null) return null;
Node<K,V> x = floor(root, key);
if (x == null) return null;
else return x.key;
}
private Node<K,V> floor(Node<K,V> x, K key) {
if (x == null) return null;
int cmp = key.compareTo(x.key);
if (cmp == 0) return x; // key와 동일한 키를 가진 노드
if (cmp < 0) return floor(x.left, key); // key보다 크다면 계속 왼쪽으로
Node<K,V> t = floor(x.right, key); // key가 클 경우, 오른쪽으로
if (t != null) return t; // 오른쪽에 작은 키가 있을 경우
else return x; // 오른쪽에 작은 키가 없을 경우
}
- 로직의 핵심: 오른쪽으로 갈 때는 나중에 답이 없을 경우를 대비해 "현재 노드를 기억하고" 오른쪽으로 가야 합니다. 만약 오른쪽 서브트리에서 아무것도(null) 안 넘어오면, 기억해둔 현재 노드가 답이 됩니다.
3. Rank 연산
rank(key)는 입력받은 키보다 작은 키가 몇 개인지 반환하는 함수입니다. (0부터 시작하므로 0이면 가장 작은 값임을 의미합니다.)
- 핵심: 각 노드에는 본인을 포함한 서브트리의 전체 노드 개수를 저장하는 n 값이 있다고 가정합니다.
- 루트와 키가 같으면: 왼쪽 서브트리의 개수(x.left.n)를 리턴합니다.
- 루트보다 작으면: 왼쪽으로 내려가서 계속 찾습니다.
- 루트보다 크면: '왼쪽 서브트리 개수 + 나(1)'를 확보한 상태에서 오른쪽으로 내려가 추가 개수를 더합니다.
[관련 코드: PDF 43페이지]
public int rank(K key) { // key보다 작은 키의 수
if (root == null || key == null) return 0;
Node<K,V> x = root;
int num = 0;
while (x != null) { // 루트부터 비교하면서 key보다 작은 키의 수를 합산
int cmp = key.compareTo(x.key);
if (cmp < 0) x = x.left;
else if (cmp > 0) { // key보다 작은 키를 갖는 노드를 발견
num += 1 + size(x.left); // 왼쪽 subtree의 노드 수를 합산
x = x.right; // 오른쪽 subtree도 계속 검사
}
else { // key값을 갖는 노드: 왼쪽 subtree만 합산
num += size(x.left); break;
}
}
return num;
}
private int size(Node<K,V> x) { return (x != null) ? x.N : 0; }- 구현 원리: 각 노드에 저장된 서브트리 크기(n 값)를 이용합니다. 루트보다 클 경우, 왼쪽 서브트리 개수와 나(루트)를 포함한 개수를 먼저 확보하고 오른쪽으로 내려가며 추가합니다.
(select랑 floor간의 관계 )_
4. Select 연산
select(rank)는 반대로 특정 등수(rank)에 해당하는 키를 찾는 함수입니다.
- 로직: 왼쪽 서브트리의 개수 t를 확인합니다.
- rank < t: 찾는 등수가 왼쪽에 있으므로 왼쪽으로 이동합니다.
- rank > t: 왼쪽 t개와 나(1개)를 제외하고 오른쪽 서브트리에서 rank - t - 1 등수를 찾습니다.
- rank == t: 현재 노드가 찾는 등수의 키입니다.
[관련 코드: PDF 44페이지]
public K select(int rank) { // rank 등수에 해당하는 키를 반환
if (root == null || rank < 0 || rank >= size())
return null;
Node<K,V> x = root;
while (true) {
int t = size(x.left);
if (rank < t) // 왼쪽 subtree의 노드 수가 rank보다 크면
x = x.left; // rank 등수의 키는 당연히 왼쪽 subtree에 있겠지
else if (rank > t) { // rank가 왼쪽 subtree의 노드 수 밖이면
rank = rank - t - 1; // 왼쪽 subtree와 부모 노드는 결과에서 제외하고
x = x.right; // 오른쪽 subtree를 조사하자
}
else // 왼쪽 subtree의 수와 rank가 일치하면
return x.key; // 부모 노드의 키를 반환 (rank의 시작은 0)
}
}


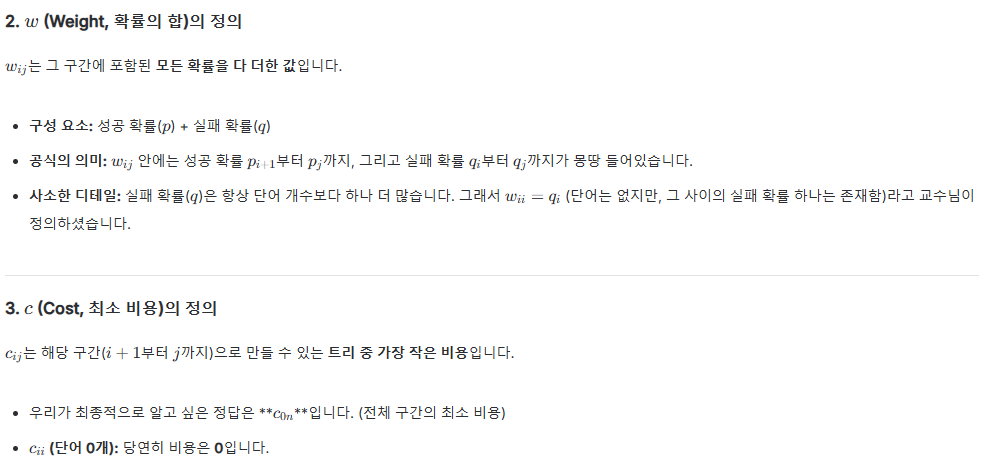
// 최적 이진 검색 트리를 찾는 함수
obst(int p[], int q[], int cost[][M], int root[][M], int weight[][M], int n)
{
int i, j, k, m, min, minpos;
for (i = 0; i < n; i++) { // 초기 조건 설정
weight[i][i] = q[i]; root[i][i] = cost[i][i] = 0;
cost[i][i+1] = weight[i][i+1] = q[i] + q[i+1] + p[i+1];
root[i][i+1] = i + 1;
}
weight[n][n] = q[n]; root[n][n] = cost[n][n] = 0;
for (m = 2; m <= n; m++)
for (i = 0; i <= n - m; i++) {
j = i + m;
weight[i][j] = weight[i][j-1] + p[j] + q[j];
k = knuth_min(cost, root, i, j);
cost[i][j] = weight[i][j] + cost[i][k-1] + cost[k][j];
root[i][j] = k;
}
}7. 연습 문제 및 직관적 풀이 (Heuristic)
교수님은 마지막으로 Twitter(0.05), Google(0.5), Apple(0.2), Facebook(0.25) 키워드 예시를 통해 문제를 풀이하셨습니다.
- 직관적 방법: 확률이 가장 큰 것을 위로 올리는 것입니다.
- Google(0.5)을 루트로 배치.
- 나머지 키들을 BST 규칙에 따라 좌우로 배치 (Google보다 큰 Twitter는 오른쪽, 작은 Apple, Facebook은 왼쪽).
- 왼쪽 서브트리에서도 확률이 더 높은 Facebook(0.25)을 위로 올립니다.
- 주의사항: 확률이 가장 높은 노드를 루트로 삼는 것이 항상 정답(최적)은 아닙니다. 확률이 비슷한 노드들이 여러 개 있을 때는 DP를 통해 정확히 계산해야 최적의 트리를 찾을 수 있습니다.







1. Floor (바닥 함수): "나보다 작거나 같은 놈 중 가장 큰 놈 찾기"
- 경우 1: 동네가 비었을 때 (null)
- 당연히 이 동네엔 답이 없습니다. "없음"을 리턴합니다.
- 경우 2: 찾는 값이 나랑 똑같을 때 (key == node.key)
- "작거나 같은 것" 중 가장 큰 걸 찾는데 똑같은 걸 찾았으니 더 볼 것도 없습니다. 내가 정답입니다.
- 경우 3: 찾는 값이 나보다 작을 때 (key < node.key)
- 나는 찾는 값보다 큽니다. 나보다 오른쪽에 있는 애들은 더 크겠죠? 이쪽은 답이 절대 없습니다.
- 재귀: "내 왼쪽 동네에 가서 다시 찾아봐!"라고 심부름을 보냅니다. 거기서 나오는 결과가 이 전체의 정답이 됩니다.
- 경우 4: 찾는 값이 나보다 클 때 (key > node.key)
- 일단 나는 찾는 값보다 작으니까 **'후보'**입니다. 하지만 내 오른쪽 동네에 나보다 크면서도 찾는 값보다는 작은, '더 좋은 후보'가 있을지 모릅니다.
- 재귀: 일단 나는 대기하고, "내 오른쪽 동네 가서 나보다 더 좋은 후보 있나 봐!"라고 보냅니다.
- 판단: 오른쪽에서 "찾았다!" 하고 누군가를 데려오면 그놈이 정답이고, 오른쪽에서 "없어" 하고 빈손으로 오면 아까 대기하던 내가 정답이 됩니다.
2. Rank (순위): "나보다 작은 놈이 총 몇 명인지 세기"
- 경우 1: 동네가 비었을 때 (null)
- 이 동네엔 나보다 작은 놈이 한 명도 없습니다. **"0명"**이라고 대답합니다.
- 경우 2: 찾는 값이 나랑 똑같을 때 (key == node.key)
- 나보다 작은 애들은 전부 내 왼쪽 동네에 모여 있습니다.
- 결과: "내 왼쪽 동네 인원수"를 리턴하면 그게 내 순위(내 앞에 있는 사람 수)입니다.
- 경우 3: 찾는 값이 나보다 작을 때 (key < node.key)
- 나는 찾는 값보다 큽니다. 나랑 내 오른쪽 동네는 셀 필요가 없습니다.
- 재귀: "왼쪽 동네로 가서 거기서만 몇 명인지 다시 세봐!"라고 시킵니다. 거기서 나온 숫자가 전체 정답입니다.
- 경우 4: 찾는 값이 나보다 클 때 (key > node.key)
- 찾는 값이 나보다 크니까, 내 왼쪽 동네 애들 전체와 **나 자신(1명)**은 무조건 찾는 값보다 작습니다.
- 확보: 일단 (왼쪽 동네 인원수 + 1명)을 확보합니다.
- 재귀: 그리고 "오른쪽 동네로 가서 거기서 몇 명인지 더 세온 다음에, 아까 내가 확보한 숫자랑 더해!"라고 시킵니다.
1. N (멤버 변수): "각 노드의 등에 써 붙인 숫자"
- PDF 31페이지와 교수님 설명을 보면, 모든 노드는 자기 몸속에 int N이라는 정보를 저장하고 있습니다.
- 이 N은 **"나를 포함해서 내 밑에 총 몇 명이 사는지"**를 미리 계산해서 적어둔 숫자입니다.
- 예를 들어, 어떤 노드의 N이 10이라면, 그 노드를 대장으로 하는 동네에 총 10명이 살고 있다는 뜻입니다.
2. t (지역 변수): "왼쪽 동네 인원수 체크용 별명"
- select(k) 함수를 실행할 때, 현재 내가 있는 노드에서 **"내 왼쪽 자식 동네에는 몇 명이 살지?"**를 확인해서 그 숫자를 t라는 이름의 변수에 잠깐 담아두는 것입니다.
- 즉, **t = (내 왼쪽 자식의 N 값)**인 셈입니다. (정확히는 자식이 없을 때를 대비해 size(x.left)라는 함수를 거쳐서 가져오죠.)
| 구분 | Floor (바닥) | Rank (순위) | Select (선택) |
| 질문 내용 | "13이랑 제일 가까운 작은 놈 누구야?" | "13보다 작은 애들 총 몇 명이야?" | "5번째 자리에 앉은 놈 누구야?" |
| 인원수(N) 활용 | 거의 안 씀 (값 비교가 우선) | 내 왼쪽 인원수를 결과에 더함 | 내 왼쪽 인원수만큼 목표에서 뺌 |
| 오른쪽 재귀 시 | "더 좋은 후보 있나 봐줘" (확인) | "지금까지 센 거에 더해서 가져와" | "앞 인원 뺐으니까 남은 등수 찾아와" |
그 null 처리 때문입니다.
왜 멤버변수(x.left.N)를 바로 쓰지 않고 **size(x.left)**라는 별도의 메소드를 거쳐서 가져오는지
'26년1학기 > 알고리즘' 카테고리의 다른 글
| 알고리즘) AVL Tree & 2-3 Tree (0) | 2026.03.30 |
|---|---|
| 알고리즘) 복습(26.3.26) (0) | 2026.03.26 |
| 알고리즘) 2장 코드 (25) | 2026.03.23 |
| 알고리즘) bst 삭제, rank,select 메소드등 (1) | 2026.03.23 |
| 알고리즘 )1주차 퀴즈 준비( 26.3.22) (1) | 2026.03.22 |