- "너 자식 하나도 없니? (isLeaf)" -> 그럼 그냥 트리 없애(root=null).
- "너 자식 딱 하나니? (!isTwoNode)" -> 그럼 그 자식을 왕으로 세워(root=자식).
- "아니라고? 그럼 너 자식 2개구나! (else)" -> 그럼 아까 배운 복잡한 **'후속자 소환술'**을 써야겠다!
(그냥 자식1,0은 루트를 제외하고 처리 )
아 else바깥이랑 다른점은, 이건 중위후속자를 찾은거기떄문에 왼쪽자식은 있을수가 없는건가, 두번째 매개변수로 자식 넣을때만 다른거고, 세번쨰 매개변수는 같은?ㅇㅇ
//자식 두개
//y는 여기서만 쓰이네
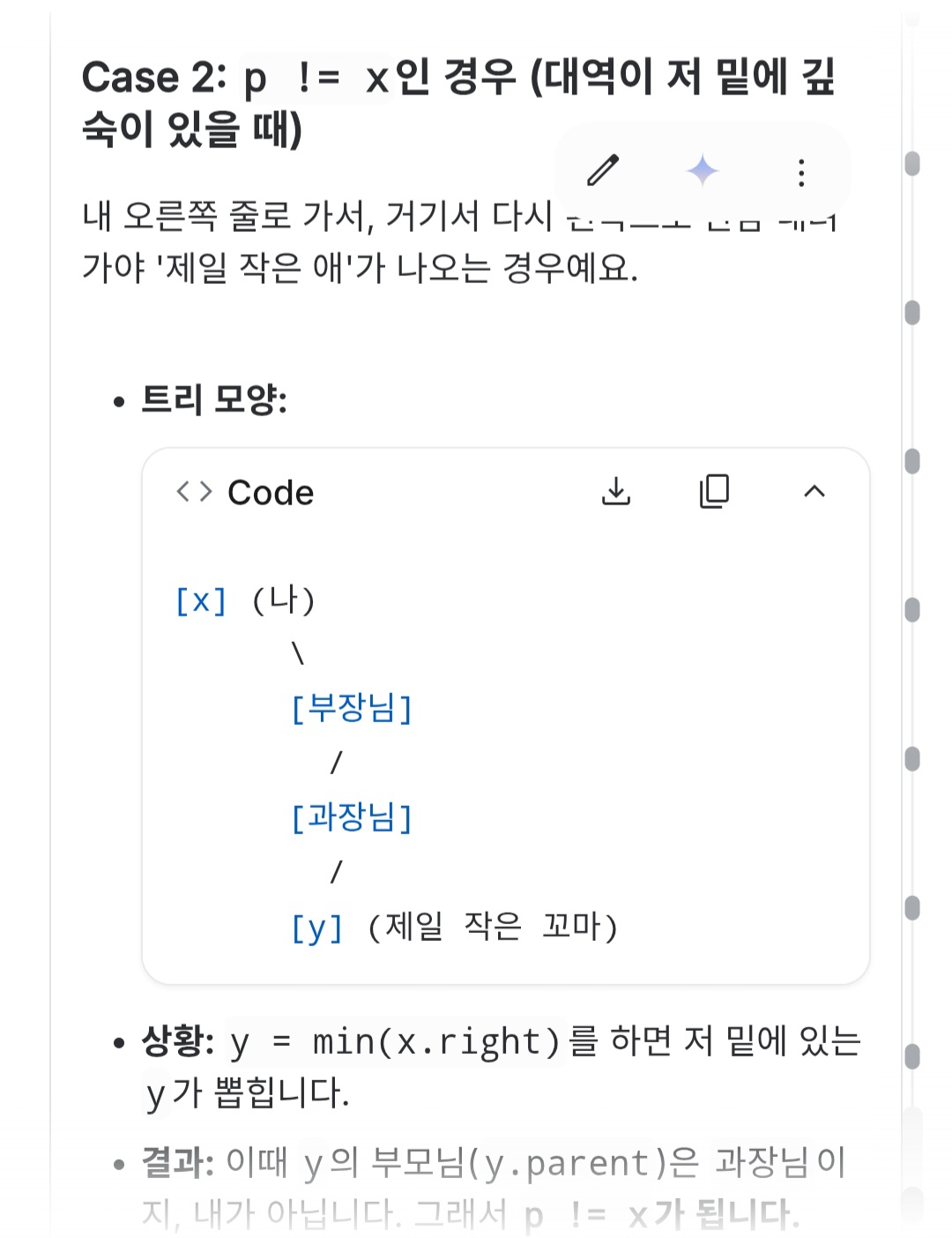
y=min(x.right);
//x를 y에 복사하는지, 그반대인지x가 우리가 없애고싶은(덮어씌우고싶은 녀석이니깐, 할당해서 처리
- 중위 후속자 (Inorder Successor): 나보다 큰 값들 중 가장 작은 값. (오른쪽 서브트리에서 가장 왼쪽 노드) -> 이미지 코드에서 사용한 방식 (y = min(x.right))
- 중위 선행자 (Inorder Predecessor): 나보다 작은 값들 중 가장 큰 값. (왼쪽 서브트리에서 가장 오른쪽 노드)
분기점 1: [특수 케이스] - 루트(Root)거나 자식이 2개일 때
(x == root || isTwoNode(x)) 부분입니다. 왜 이 둘을 묶었을까요? **"일반적인 방법으로는 삭제가 안 되는 애들"**이기 때문입니다.
- 루트(Root)인 경우: 위로 연결할 부모님이 없죠? 그래서 특별 관리가 필요합니다.
- 자식이 없으면? 그냥 트리 삭제 (root = null)
- 자식이 1개면? 그 자식을 왕(root)으로 승격 (root = 자식)
- 자식이 2개인 경우: 누가 루트든 아니든 상관없이, 중간에 이 빠진 것처럼 구멍이 크게 납니다. 그래서 **'후속자(successor)'**를 데려와서 값을 채우는 특별한 작업이 필요합니다.
결론: "야, 복잡한 놈들(루트 or 자식 2개) 다 이리로 모여봐!" 하고 첫 번째 if에서 걸러낸 겁니다.
분기점 2: [일반 케이스] - 루트도 아니고 자식도 1개 이하일 때
맨 오른쪽 아래 else 부분입니다. 여기가 "가장 쉬운 삭제" 상황입니다.
- 나는 루트가 아니니까 **부모님(p)**이 확실히 계십니다.
- 자식은 0개 아니면 1개뿐입니다.
- 해결법: 그냥 내 부모님(p)이랑 내 자식(x.left나 x.right)을 **직접 연결(relink)**시켜버리고 나는 쏙 빠지면 됩니다. (이게 제일 깔끔한 삭제입니다.)
treesearch는 키값을 리턴하주던가 , 왜 밸류값이 아니라, 근데 키값 리턴하면 의미있나, 머지,
아 노드 그자체 리턴해서
노드.value로 밸류 알아낼수있도록?ㅇㅇ
if (x == root || isTwoNode(x)) {
if (isLeaf(x)) { // 1) 자식 0개인 '루트' (자식 2개는 아니니까 무조건 루트임)
root = null; // -> 트리 폭파
}
else if (!isTwoNode(x)) { // 2) 자식 1개인 '루트' (자식 2개 아니니까 여기도 무조건 루트임)
root = (자식); // -> 자식을 왕으로 승격
}
else { // 3) 자식이 2개인 경우 (루트든 아니든 상관없음!)
// 후속자 찾아서 값 복사 (복잡한 수술)
}
}젤 처음 두개는 루트 처리를 위해서였네ㅔ
(갑자기 왜 자식 1개처리하는지 이상했는데 )
(바깥에서 if에 걸리고,
안쪽 조건문에서 자식 2명은, 루트이던 아니건 동일하게 처리
y=min(x.right);
x.key=y.key; //진짜 연결리스트를 옮겨주는게 아니라 값 복사
x.value=y.value;
//그러면 이제 삭제가 된건가,
이러면 원래 y자리에 있던건 그대로 y아닌가 relink가 해주나 ㅇㅇ
p = y.parent; // 3. 원래 y의 부모를 찾음
이때 p의 의미가
(아무튼 실제 삭제는 아니고 연결만 끊는거네 )< 가비지 가 ..함
y가 자식이 없어도 null이랑 원래 y의 부모랑 연결해주겟다는의미인가,
근데 원래 부모의 왼쪼게 달아야하나 오른쪽에 달아야하나 이걸 모르겟으 ㅁ
상황 B: y가 부모의 오른쪽 자식인 경우 (특수한 경우)
- 만약 x.right에 자식이 하나도 없어서 x.right가 바로 y가 된 상황이라면?
아 y와 y자식간의 관계가 아니라 yㅇ와 원래 부모와의 관계가 중요한가 왜지
음 아마 진짜 y는 이제 없어지고 원래 y자리에 들어와야하니깐, y의 역할을 대신해줘하니깐?ㅇㅇ
1. 루트(Root)일 때 (첫 번째 if 안쪽)
- 상황: 나는 이 트리의 **최고 우두머리(왕)**입니다. 내 위에는 아무도 없어요.
- 지울 때: 내가 사라지면 **트리 전체의 주인(root 변수)**이 바뀌어야 합니다.
- 코드의 의미:
- root = null; (내가 마지막이었으면 이제 트리는 텅 빈다.)
- root = x.left; (내가 죽으면 내 아들이 새로운 왕이다.)
- 특징: relink 같은 건 안 씁니다. 왜냐? 나를 붙여줄 부모님이 없으니까요. 그냥 root라는 시스템 변수 자체를 갈아 끼우는 겁니다.
2. 루트가 아닐 때 (가장 바깥쪽 else)
- 상황: 나는 중간 관리자나 말단 사원입니다. 내 위에는 **부모님(p)**이 계십니다.
- 지울 때: 내가 사라져도 트리 전체의 주인(root)은 그대로입니다. 다만 내 부모님이 내 자식을 직접 챙기도록 "다리만 놓아주면" 됩니다.
- 코드의 의미:
- p = x.parent; (일단 내 상사를 부릅니다.)
- relink(p, 자식, ...); (상사한테 내 자식 손을 쥐여줍니다.)
- 특징: root 변수는 건드리지 않습니다. 부모님(p)의 손(left 또는 right)만 고쳐줍니다.








🌳 이진 탐색 트리(BST) 삭제
1. 자식이 없는 경우 (리프 노드)
- 방법: 그냥 삭제 (연결만 끊기)
- 한마디: "혼자니까 그냥 퇴근!"
2. 자식이 하나인 경우
- 방법: 내 자리를 내 자식에게 물려주기 (부모와 내 자식을 직접 연결)
- 한마디: "내 뒤에 선 사람, 우리 엄마 손 잡아!"
3. 자식이 둘인 경우
- 방법: **'대역'**을 찾아 내 자리에 앉히기
- 대역 찾기: 오른쪽 줄에서 가장 작은 사람(Inorder Successor)을 선택.
- 값 복사: 그 사람의 숫자를 내 자리로 가져옴.
- 대역 삭제: 원래 대역이 있던 자리는 1번이나 2번 방법으로 정리.
- 한마디: "제일 비슷한 대타 데려와서 내 이름표 달아주고, 걔 원래 자리는 치워!"

/* 1. Node 구조: 미래를 위해 확장 가능하게 설계됨 */
class Node<K, V> {
K key;
V value;
int n; // 자손 노드 수 + 1. 이 값을 유지해야 랭킹(7등 찾기 등) 연산을 빨리 할 수 있음.
int aux; // AVL 트리(높이 차이)나 레드-블랙 트리(색상) 등 하위 클래스에서 속성을 줄 용도.
Node<K, V> left, right;
Node<K, V> parent; // 부모를 가리키는 포인터가 있어야 AVL이나 RB 트리 구현이 훨씬 쉬워짐.
public Node(K key, V val) {
this.key = key;
this.value = val;
this.n = 1; // 리프 노드는 자기 자신뿐이므로 초기값은 1.
}
}
/* 2. 트리 검색 내부 함수: 삽입 위치까지 찾아주는 핵심 로직 */
protected Node<K, V> treeSearch(K key) {
Node<K, V> x = root; // 모든 연산은 루트부터 시작해서 내려감.
while (true) {
int cmp = key.compareTo(x.key);
if (cmp == 0) return x; // 찾았으면 바로 그 노드를 반환하고 종료.
else if (cmp < 0) { // 찾고자 하는 키가 작으면 왼쪽으로 내려감.
if (x.left == null) return x; // 더 못 내려가면 마지막 노드라도 반환(여기에 새 노드 붙일 거니까).
else x = x.left;
} else { // 키가 더 크면 오른쪽으로 내려감.
if (x.right == null) return x; // 오른쪽이 비었으면 마지막 노드 반환.
else x = x.right;
}
}
// 비교 횟수는 결국 이 노드가 몇 번째 레벨(깊이)에 있느냐와 똑같음.
}
/* 3. 데이터 삽입: 리프 노드에 달고 위로 올라가며 n값 갱신 */
public void put(K key, V val) {
if (root == null) {
root = new Node<K, V>(key, val);
return;
}
Node<K, V> x = treeSearch(key); // 일단 검색해서 어디에 붙을지(또는 업데이트할지) 찾음.
int cmp = key.compareTo(x.key);
if (cmp == 0) x.value = val; // 이미 키가 있으면 밸류만 새로운 값으로 업데이트.
else {
Node<K, V> newNode = new Node<K, V>(key, val);
if (cmp < 0) x.left = newNode; // 작으면 왼쪽에 새 노드 추가.
else x.right = newNode; // 크면 오른쪽에 새 노드 추가.
newNode.parent = x; // 부모-자식 관계를 확실히 연결해줌.
// 새로 추가됐으니 루트까지 조상들의 n(노드 수)을 1씩 다 증가시켜줘야 함.
rebalanceInsert(newNode);
}
}
/* 4. 리링크(Relink): 교수님이 '기똥차다'고 언급한 유틸리티 */
protected void relink(Node<K, V> parent, Node<K, V> child, boolean makeLeft) {
// x가 있던 자리에 자식 c를 대신 붙여주는 연산을 아주 심플하게 해결함.
if (child != null) child.parent = parent;
if (makeLeft) parent.left = child; // 트루면 왼쪽에 붙이고,
else parent.right = child; // 폴스면 오른쪽에 붙임.
}
/* 5. 노드 삭제: 가장 골치 아픈 '자식이 둘인 경우' 포함 */
public void delete(K key) {
if (root == null) return;
Node<K, V> x = treeSearch(key);
if (!key.equals(x.key)) return; // 지울 키가 없으면 그냥 리턴.
// 케이스 1 & 2: 자식이 없거나 하나인 경우 (루트 포함)
if (x == root || !isTwoNode(x)) {
if (isLeaf(x) && x == root) { root = null; return; } // 마지막 남은 노드 지우기.
// 자식이 하나라면 그놈을 내 위치로 올려서 부모와 연결함.
// 삭제 후엔 위로 올라가며 n값을 1씩 빼주는 과정(rebalanceDelete)이 필요함.
}
// 케이스 3: 자식이 둘인 노드 삭제 (가장 복잡함)
else {
// 이노더 석세스(내 다음 데이터)를 찾음: 오른쪽으로 한 번 가서 왼쪽 끝까지 내려감.
Node<K, V> y = min(x.right);
x.key = y.key; // 석세스의 키를 내 위치로 복사(덮어쓰기).
x.value = y.value;
// 실제로 지우는 건 값을 빌려준 y임. y는 왼쪽 자식이 없으므로 케이스 1이나 2가 됨.
Node<K, V> p = y.parent;
relink(p, y.right, y == p.left); // y의 오른쪽 자식을 y의 부모에게 연결.
rebalanceDelete(p, y); // y가 지워졌으니 조상들의 n값을 1씩 줄임.
}
}
/* 6. n값 관리: 데이터 이동이 없으므로 일관성 유지가 중요 */
private void resetSize(Node<K, V> x, int value) {
// 루트가 널일 때까지 부모를 타고 올라가며 n값을 갱신함.
// 풋 할 때는 +1, 딜리트 할 때는 -1을 해줌으로써 전체 트리의 노드 수 정보를 유지함.
for (; x != null; x = x.parent)
x.n += value;
}
// - 하지만 배열은 삽입/삭제 시 데이터를 다 밀어야 하는 부담이 큼.
// - BST는 데이터를 옮길 필요 없이 밑에 새로 달아주면 되니까 삽입(Put)에서 장점이 있음.
public class BinarySearchST<K extends Comparable<K>, V> {
private K[] keys;
private V[] vals;
private int N;
/* 교수님 설명: "이진 검색의 핵심은 내가 찾으려는 키의 위치(인덱스)를 로그 N만에 찾는 것" */
private int search(K key) {
int lo = 0, hi = N - 1;
while (lo <= hi) {
int mid = (hi + lo) / 2;
int cmp = key.compareTo(keys[mid]);
if (cmp < 0) hi = mid - 1;
else if (cmp > 0) lo = mid + 1;
else return mid; // 키를 찾았을 때 인덱스 반환
}
return lo; // 키가 없을 경우, 이 키가 들어가야 할 적절한 '위치'를 반환함
}
/* 교수님 설명: "배열에서 데이터를 넣는 건(Put) 상당히 부담스러운 일이다." */
public void put(K key, V val) {
int i = search(key);
// 이미 키가 있으면 값만 업데이트(로그 N 검색)
if (i < N && keys[i].compareTo(key) == 0) {
vals[i] = val; return;
}
// 없으면 새로 넣어야 하는데, 배열이 꽉 찼으면 2배로 늘림
if (N == keys.length) resize(2 * keys.length);
/* 중요: "원하는 자리를 비우기 위해 뒤에 있는 데이터를 한 칸씩 다 밀어야 한다(이동 부담)." */
for (int j = N; j > i; j--) {
keys[j] = keys[j-1]; vals[j] = vals[j-1];
}
keys[i] = key; vals[i] = val; N++;
}
/* 교수님 설명: "지울 때도 마찬가지로 빈 공간을 채우기 위해 앞으로 데이터를 다 당겨줘야 한다." */
public void delete(K key) {
if (isEmpty()) return;
int i = search(key);
if (i == N || keys[i].compareTo(key) != 0) return; // 지울 게 없음
/* "뒤에 있는 데이터를 앞으로 복사해서 한 칸씩 당긴다." */
for (int j = i; j < N - 1; j++) {
keys[j] = keys[j+1]; vals[j] = vals[j+1];
}
N--;
keys[N] = null; vals[N] = null; // "가비지 컬렉션(GC)이 되도록 명시적으로 널 처리를 해주는 게 좋은 습관이다."
// 데이터가 너무 적어지면(1/4) 배열 크기를 줄임
if (N > 0 && N == keys.length / 4) resize(keys.length / 2);
}
}

'26년1학기 > 알고리즘' 카테고리의 다른 글
| 알고리즘) 강의 (26.3.25) (0) | 2026.03.25 |
|---|---|
| 알고리즘) 2장 코드 (25) | 2026.03.23 |
| 알고리즘 )1주차 퀴즈 준비( 26.3.22) (1) | 2026.03.22 |
| 알고리즘 )1주차 퀴즈 준비_코드( 26.3.21) (0) | 2026.03.21 |
| 알고리즘 )1주차 퀴즈 준비_( 26.3.21) (0) | 2026.03.21 |