.
2pmm
출력 버퍼의 동작 (데이터가 하나만 있어도 쓰는지?)
아니요, 하나만 있다고 바로 디스크에 쓰지 않습니다. 외부 정렬의 핵심은 느린 디스크 I/O 횟수를 줄이는 것이므로 최대한 효율적으로 움직입니다.
. 입력 블록을 다 읽었을 때 (입력 버퍼가 비었을 때)
네, 맞습니다. 특정 런(Run)에서 가져온 입력 버퍼의 데이터를 모두 사용하여 버퍼가 비게 되면, 최솟값 찾기(비교 연산)를 잠시 멈추고 해당 런의 다음 블록을 디스크에서 메모리로 읽어오는 작업을 먼저 수행합니다
ㅡ안그러면 최솟값을 제대로 못찾음
ㅡ병합이 제대로안됨
애초에 정렬하기위함인데

로그 두개 나올때 각각 로그가 무슨뜻인지



(이유가 뭐더라)
else if(less(aux[j],aux[i])){
a[k]=aux[j++];
}지금 a에 쓰고있으니깐
aux에서 읽어와야지

//어디로 복사해야할지,
//무엇을 참조해야하늕
//어디에 써야하는지 헷갈리면,
//a가 결과라는점 생각해보면
- 작성하신 코드: else if(less(a[j], a[i])) (X)
- 수정: else if(less(aux[j], aux[i])) (O)
왜 재귀 sort가 끝난 다음에 검사해야 하나요?
Skip Merge의 핵심 아이디어는 **"왼쪽 그룹과 오른쪽 그룹이 각각 이미 정렬되어 있을 때, 왼쪽의 가장 큰 값(a[mid])이 오른쪽의 가장 작은 값(a[mid+1])보다 작거나 같다면 전체가 이미 정렬된 상태다"**라는 것입니다.
- 재귀 호출 전 (잘못된 위치): 왼쪽 그룹(lo~mid)과 오른쪽 그룹(mid+1~hi)이 아직 정렬되지 않은 상태입니다. 이때 a[mid]와 a[mid+1]을 비교하는 것은 아무런 의미가 없습니다.
- 재귀 호출 후 (정확한 위치):
- sort(a, aux, lo, mid); 호출이 끝나면 왼쪽 절반이 정렬됩니다.
- sort(a, aux, mid+1, hi); 호출이 끝나면 오른쪽 절반이 정렬됩니다.
- 이제 두 그룹의 경계선(mid, mid+1)을 비교해 봅니다.
- 만약 a[mid] <= a[mid+1]이라면, 두 그룹을 합쳐도(merge) 순서가 바뀌지 않으므로 병합 과정을 통째로 건너뛰는 것입니다.
sort(a, aux, lo, mid)라는 코드를 실행하는 순간을 **"정렬 주문을 넣는 것"**이라고 생각해 보세요.
cutoff있을때
lo>=hi조건문 필요없나,
Cutoff 부분의 return 누락
if (hi - lo <= cut - 1) {
Insertion.sort(a, lo, hi);
return; // ★ 반드시 return이 있어야 아래 재귀 코드로 안 넘어갑니다!
}
public static void sort(Comparable[] a, int lo, int hi) {
//시간복잡도를 생각해보면 이중 for문이라는거
for (int i = lo+1; i <=hi ; i++) {
for (int j = i; j >lo && less(a[j],a[j-1]); j--) {
//범위 이렇게 맞나
exch(a,j,j-1);
}
}
}
"정렬된게 aux에 들어있지 않나?"
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
merge안에서
a[k]=aux[i++]
혹은
a[k]=aux[j++]
해주는데 그걸 안해주니깐
// 1단계: a를 재료로 써서 aux에 왼쪽 절반을 정렬해둬!
sort(aux, a, lo, mid);
// 2단계: a를 재료로 써서 aux에 오른쪽 절반을 정렬해둬!
sort(aux, a, mid + 1, hi);
// [중요 시점]
// 지금 정렬된 왼쪽/오른쪽 데이터는 어디에 들어있을까요?
// 바로 'a' 배열에 들어있습니다! (위에서 aux를 재료로 a에 담으라고 했으니까요)그런데 이 함수의 최종 목표는 무엇인가요?
결과물을 aux 배열에 담아주는 것입니다.
- 평소대로라면: merge(a, aux, lo, mid, hi)를 호출합니다. 이 함수는 a에 있는 데이터를 합치면서 aux로 옮겨줍니다. 약속이 지켜졌죠?
- Skip Merge 상황이라면: a[mid] <= a[mid+1]이라서 합칠 필요가 없습니다. 하지만! 데이터는 여전히 **a**에 있습니다. 그냥 return 해버리면, 이 함수를 부른 쪽에서는 aux에 결과가 있을 줄 알고 열어봤는데 데이터가 옛날 그대로인 상태가 됩니다.
// [개선 2] Skip Merge
// 위에서 결과를 a에 담으라고 했으니, 지금 데이터는 a에 정렬되어 있음.
if (less(a[mid], a[mid + 1])) {
// ★ 하지만 이 함수의 최종 목적지는 aux임!
// 병합은 안 하더라도, a에 있는 데이터를 aux로 옮겨는 줘야 함.
System.arraycopy(a, lo, aux, lo, hi - lo + 1);
return;
}
성능개선3
젤처음 복사
왜
배열 크기가 1이 되어 재귀가 멈출 때, 데이터를 src에서 dst로 옮겨주는 코드가 없기 때문에 문제가 생기는 것입니다.
3. 처음에 복사를 해두면 어떻게 될까? (해결책)
핑퐁 방식은 일반적인 머지 소트처럼 merge 직전에 매번 복사하지 않습니다. 대신 **재귀의 맨 밑바닥(크기 1)**에서 아무것도 안 하고 올라오는데, 이때 결과 그릇(dst)이 비어있으면 안 되기 때문에 시작할 때 딱 한 번 전체를 복사해 두는 것입니다.
"크기가 1일 때만 문제 아냐?"라고 생각할 수 있지만, 핑퐁(역할 교체) 방식의 특성 때문에 배열 크기가 2든 100이든 상관없이 처음 복사(arraycopy)를 안 하면 모든 정렬이 깨지게 됩니다.
친구에게 **"접시 A에 있는 사과 1개를 접시 B로 정렬해서 옮겨줘"**라고 시켰다고 해봅시다.
- 접시 A: [사과]
- 접시 B: [ ] (빈 접시)
- 친구의 생각: "사과가 1개네? 1개는 이미 정렬된 거니까 할 일 없음! 끝(return)!"
- 결과: 친구가 일을 마쳤다고 해서 접시 B를 봤더니... 여전히 빈 접시입니다! 사과는 아직 접시 A에 있죠.
이게 문제입니다. 정렬을 시킨 사람은 접시 B에 사과가 있을 줄 알고 다음 요리를 하려는데, 접시 B가 비어있으니 요리가 망가지는 거예요.

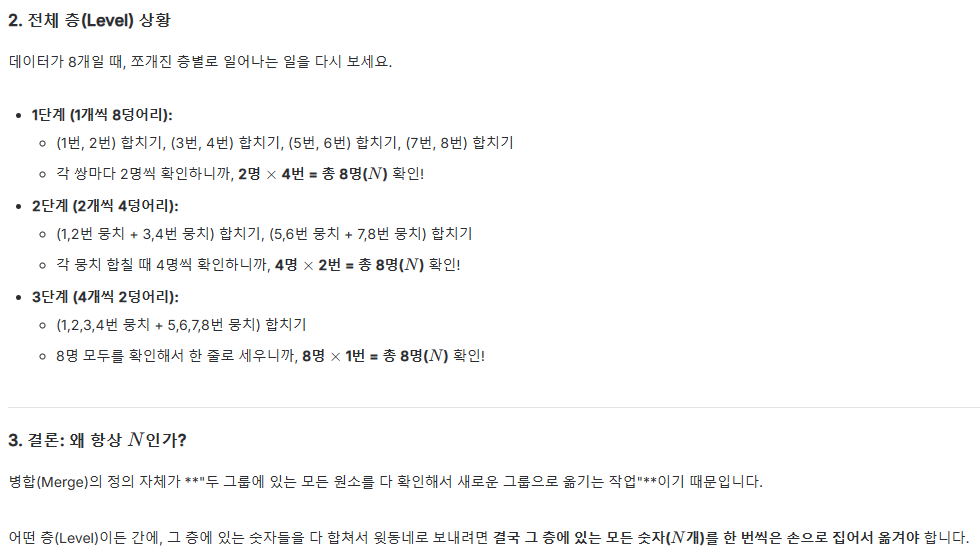
Q: "소문자 n은 부분 크기인건가?"
- A: 네, 맞습니다. **대문자 N**은 배열 전체의 길이를 의미하고, **소문자 n**은 현재 단계에서 정렬된 상태인 **"부분 배열의 크기"**를 의미합니다. (1개씩 묶기 -> 2개씩 뭉치기 -> 4개씩 뭉치기...)
Q: "왜 스왑(Ping-pong)을 내부 반복문이 끝나고 해야 하지?"
- A: 내부 반복문(j 루프)은 **"배열 전체를 훑으며 크기 n짜리 덩어리들을 모두 dst로 병합하는 한 번의 과정(Pass)"**입니다.
- j 루프가 도는 동안에는 src는 오직 재료로만, dst는 오직 결과 그릇으로만 쓰여야 데이터가 꼬이지 않습니다.
- 모든 배열 원소가 src에서 dst로 정렬되어 옮겨진 후에, 다음 단계(크기 2n)에서는 방금 만든 dst를 다시 재료(src)로 쓰기 위해 루프 밖에서 교체하는 것입니다.
Q: "매개변수 순서가 성능개선 3번(핑퐁)이랑 같네?"
- A: 정확합니다! in은 데이터를 읽어오는 src(aux), out은 데이터를 쓰는 dst(a) 역할을 합니다. 매 단계마다 merge(src, dst, ...)를 호출하므로 슬라이드 34페이지의 핑퐁 방식과 원리가 같습니다.
- 작성하신 코드: for (int n = 1; n < N; n++)
- 수정 사항: for (int n = 1; n < N; n *= 2)
- 이유: Bottom-Up 방식은 병합하는 배열의 크기를 1, 2, 4, 8... 순으로 두 배씩 키워가야 합니다.
'26년1학기 > 알고리즘' 카테고리의 다른 글
| 알고리즘) 2장 코드 (25) | 2026.03.23 |
|---|---|
| 알고리즘) bst 삭제, rank,select 메소드등 (1) | 2026.03.23 |
| 알고리즘 )1주차 퀴즈 준비_코드( 26.3.21) (0) | 2026.03.21 |
| 알고리즘 )1주차 퀴즈 준비_( 26.3.21) (0) | 2026.03.21 |
| 알고리즘 )1주차 이론 etc..( 26.3.20) (0) | 2026.03.20 |